最近更新.rss.xml
最近实践
note https://z2h.cn/hanzi 字帖生成网站,田字格
note 仿苹果液态玻璃效果
note amd 利用 npu 的办法:https://ryzenai.docs.amd.com/en/latest/inst.html
https://lemonade-server.ai/ https://github.com/amd/gaia?tab=readme-ov-file
主要还是 lemonade-server ,gaia 也是连接的 gaia (直接安装 gaia 会自动安装 lemonade-server
好文推荐 https://vue-bits.dev/ 非常绚酷的 vue 动画库
好文推荐 浏览器插件开发最佳实践 https://wxt.dev/guide/installation.html
好文推荐 前端开发的瓶颈与未来之路
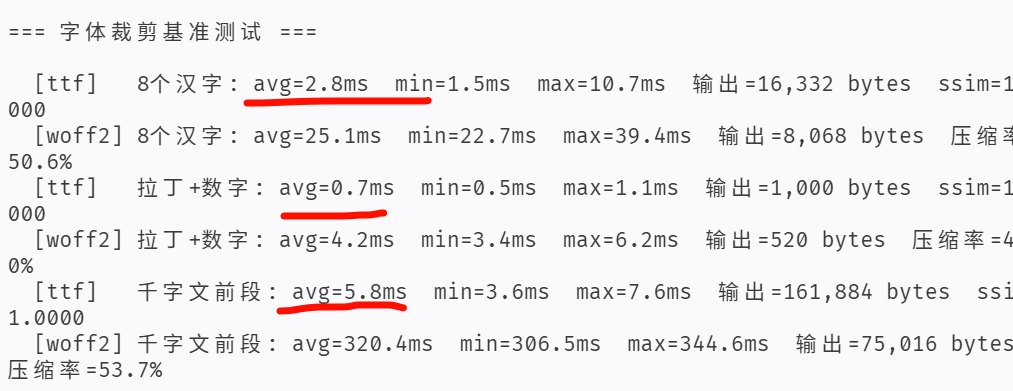
可以看到 woff2 格式更是二十多倍的速度提升,而 ttf 格式也有了接近 20% 的性能提升。
这是一个在线动态字体裁剪服务,上次经过 5.1 的优化 ttf 已经达到了毫秒级动态裁剪
以后只需要等待大模型进化就可以自然得到项目性能提升了
由此可见 5.2 较之 5.1 是更聪明的,并且这次还是只跑了两小时,之前 5.1 我是 loop 模式跑了好几个晚上。
这次使用同样的提示词跑了两个小时得到的性能结果如下,并且还修复了一个 otf 字体转换的bug

在之前我就尝试使用 glm5.1 优化过我的 webfont 项目的性能:cc loop 模式自动优化代码性能实战
下面是上次的优化结果
现在 glm5.2 发布了,我打算再尝试一下 glm5.2 的能力如何,因为之前使用 5.1 loop 模式已经达到了优化极限也就是连续跑一个晚上也没有新的新能提升
实践
昨天晚上让 glm-5-turbo 自己跑了一晚上优化,今天早上被震惊了,ai是真厉害啊
将一个成熟的开源库的性能居然能优化快了足足接近十倍多了,太强了

开场
最近到处都能看到"前端已死"、"前端工作快保不住了"这类文章。
我每次看到都忍不住想吐槽——为啥不说后端已死?是因为看不懂后端代码吗?
核心论点:AI 其实更擅长后端
但凡真正用 AI 写过项目并上线的人都能感受到——AI 明明更擅长后端。从需求到测试,整条链路 AI 都能跑通闭环。
但前端不行,前端必须要有人在回路中盯着。哪怕用最好的视觉模型,也只能减少一部分工作量,还是需要人去处理各种细节。
同样的任务,用 AI 开发后端和前端,一定是后端先完成。前端消耗的 token 也更多。
为什么自媒体总发"前端已死"?
所以我想了想,这些自媒体一直发"前端已死"的文章,说到底就是——前端有视觉冲击力,好吸粉。
后端呢?即便 AI 能全链路构建一个后端程序,但它没有东西可以给别人看。观众根本感受不到 AI 对后端的冲击力。除非他自己去试过,但试过的人终究是少数。
前端焦虑年年有,年年上热搜。为什么?因为前端能出效果、好看。一篇"前端已死"配上 AI 生成的网页截图,传播量分分钟十万加。
结论
前端的困境被无限放大,后端的危机被默默消化。这不代表前端更危险,只代表前端更上镜。
真要说 AI 取代,后端那些重复性的增删改查、配置编写、测试生成,一样在被 AI 吃掉。只是没人拍成短视频,因为压根就爆不了。
在 AI 面前,大家其实是人人平等的。但前端站在了这个时代的聚光灯下,每一道皱纹都被拍得清清楚楚。
最后我想说——AI 应用时代,一定是前端的时代。Claude、所有 AI 时代的主流应用,都是前端技术栈构建的。传统后端占比极小。
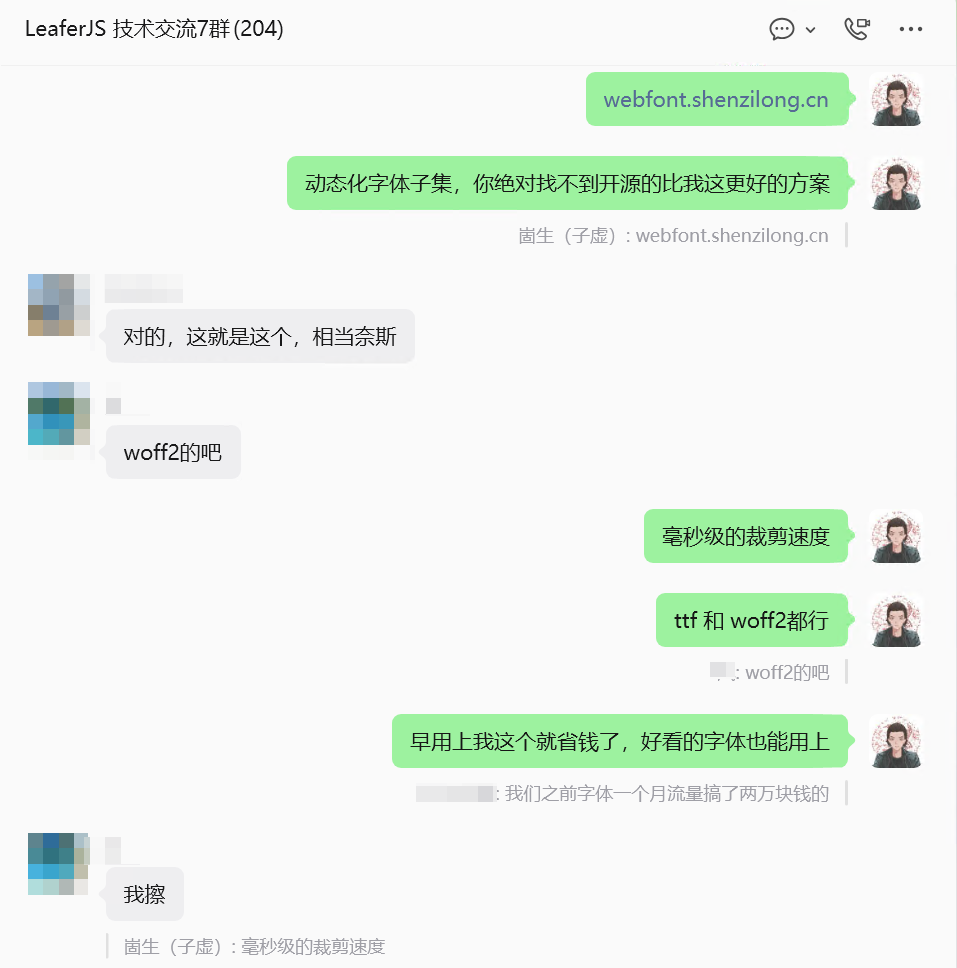

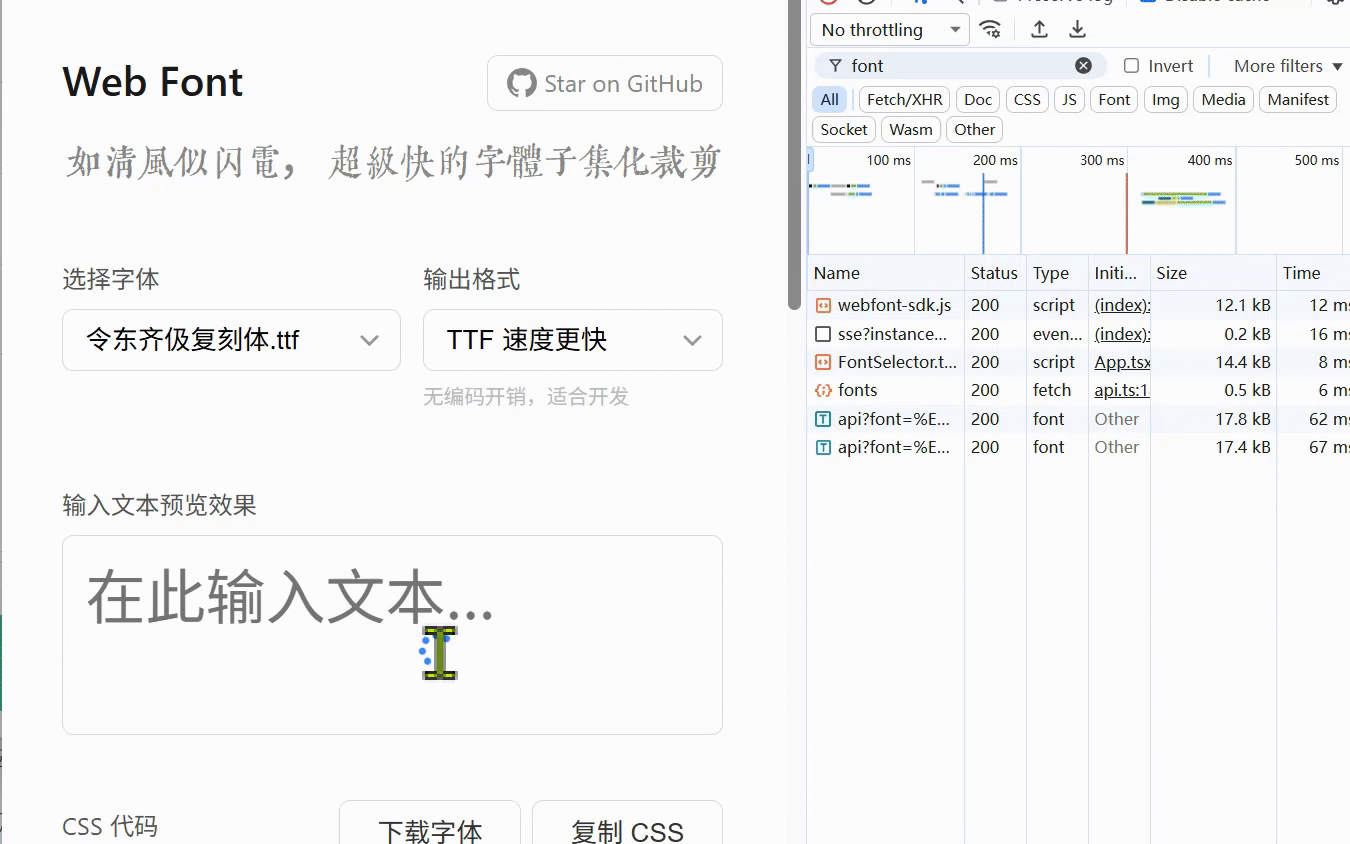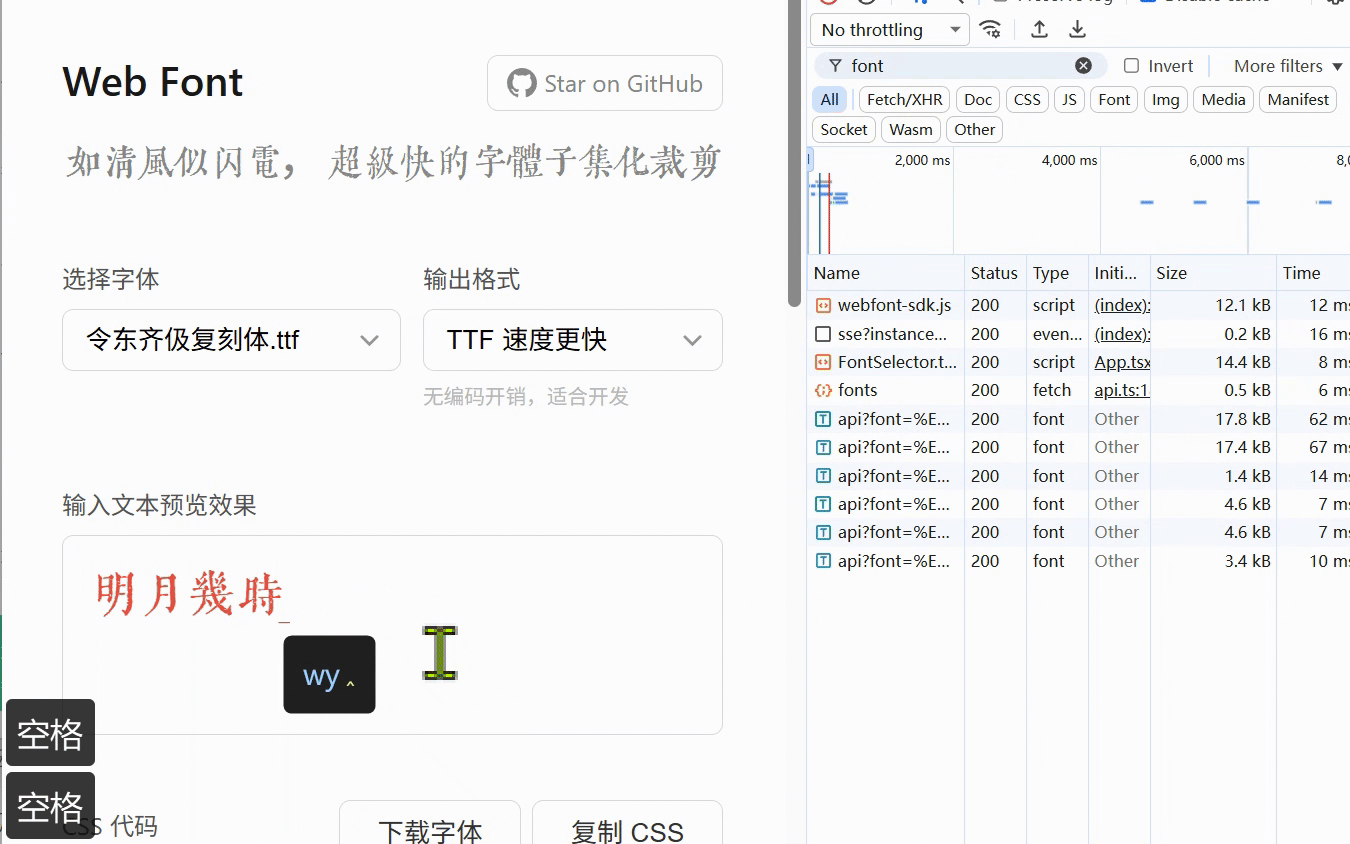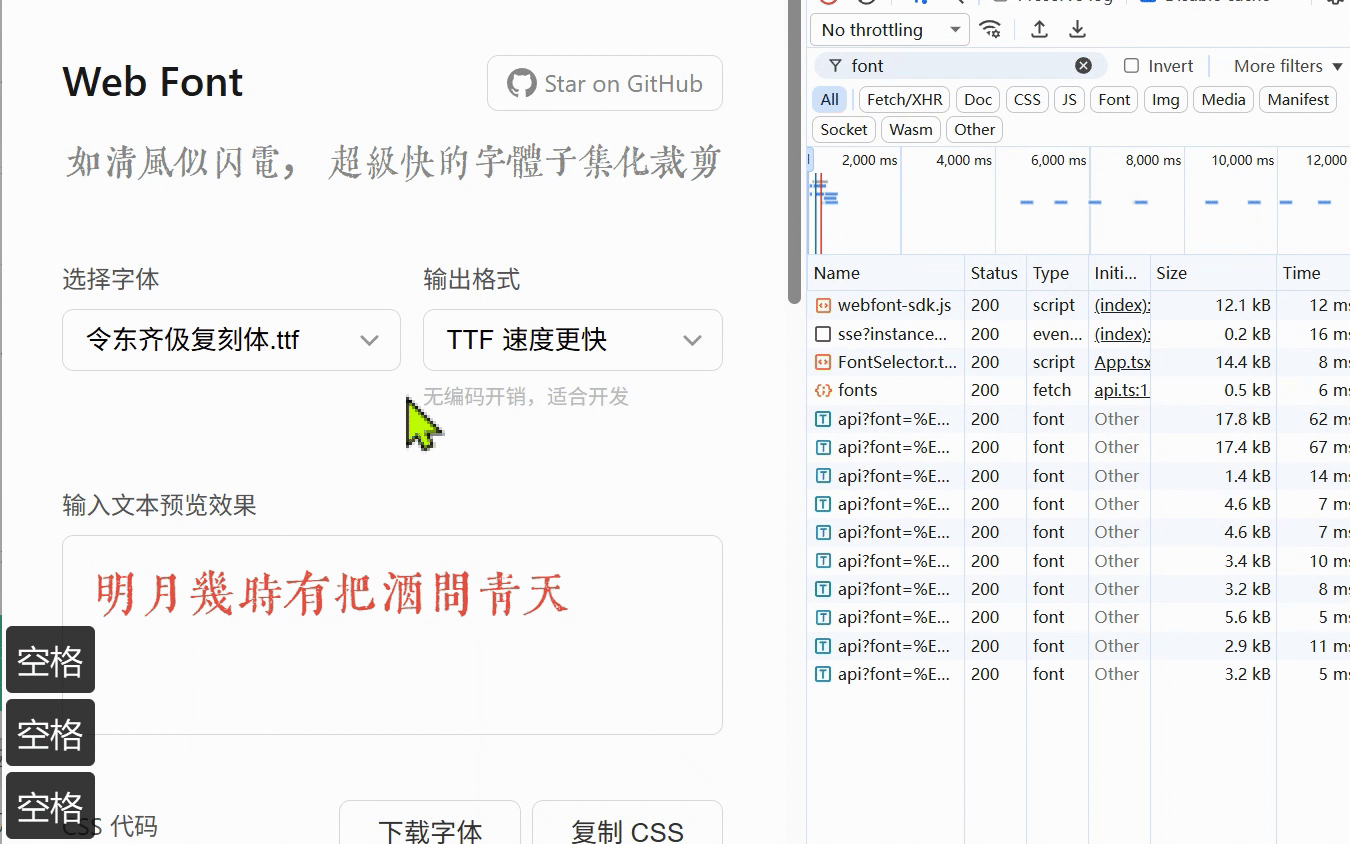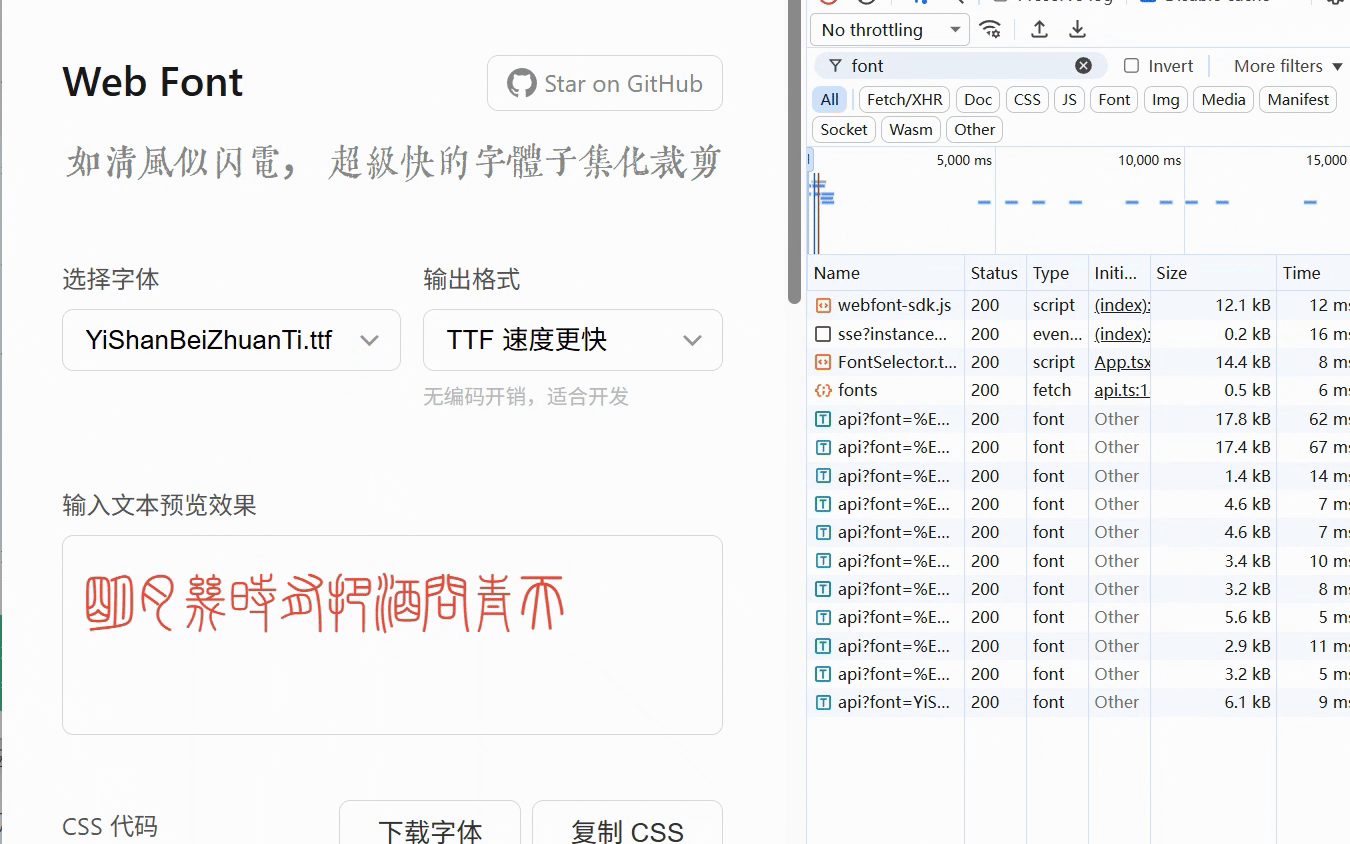
如果大家有需要选择需要动态加载字体的话就可以尝试一下我这个
webfont 使用 node 运行时的裁剪速度:
于是我赶快向群友推荐了我的项目:https://webfont.shenzilong.cn/,这个项目在2020年就已经上了阮一峰的期刊
这里和大家解释一下,一些富文本或制作图片海报之类的应用会支持选择各种丰富的字体
而一个中文字体动辄几十兆,多则数百兆。
国内1GB的公网流量基本上可以视为需要将近五六毛钱
所以如果全量加载字体用户量一多很容易就会烧出大额流量费用账单
这里和大家解释一下,一些富文本或制作图片海报之类的应用会支持选择各种丰富的字体
所以如果全量加载字体用户量一多很容易就会烧出大额流量费用账单
( 图中应群友要求打码)
国内1GB的公网流量基本上可以视为需要将近五六毛钱
而一个中文字体动辄几十兆,多则数百兆。
今天照例逛各大技术群,一位群友说他们之前字体流量一个月花了两万多块钱
我自己独立想出的一种agent的UI方案,结果我现在发现MCP UI或者说MCPAPP人家早在半年前就已经想出来了,唉,被人领先了半年啊,不过我觉得这个东西倒未必非要和MCP绑定
让 Claude Code 等工具自动切换模型:图片走多模态,代码走 DeepSeek,把模型选择权从 AI 工具手里抢回来
我经常使用各类ai工具还有多个llm服务商的api,这导致我想要切换某个工具的模型非常麻烦,而且有些工具只支持 openai 风格的调用,有些工具只支持anthropic风格的,服务商也是,有些两种风格都提供了,有些是只有单一风格的。
于是我萌发了做一个llm网关的想法,核心玩法是可以配置路由规则来根据请求动态切换服务商和模型。
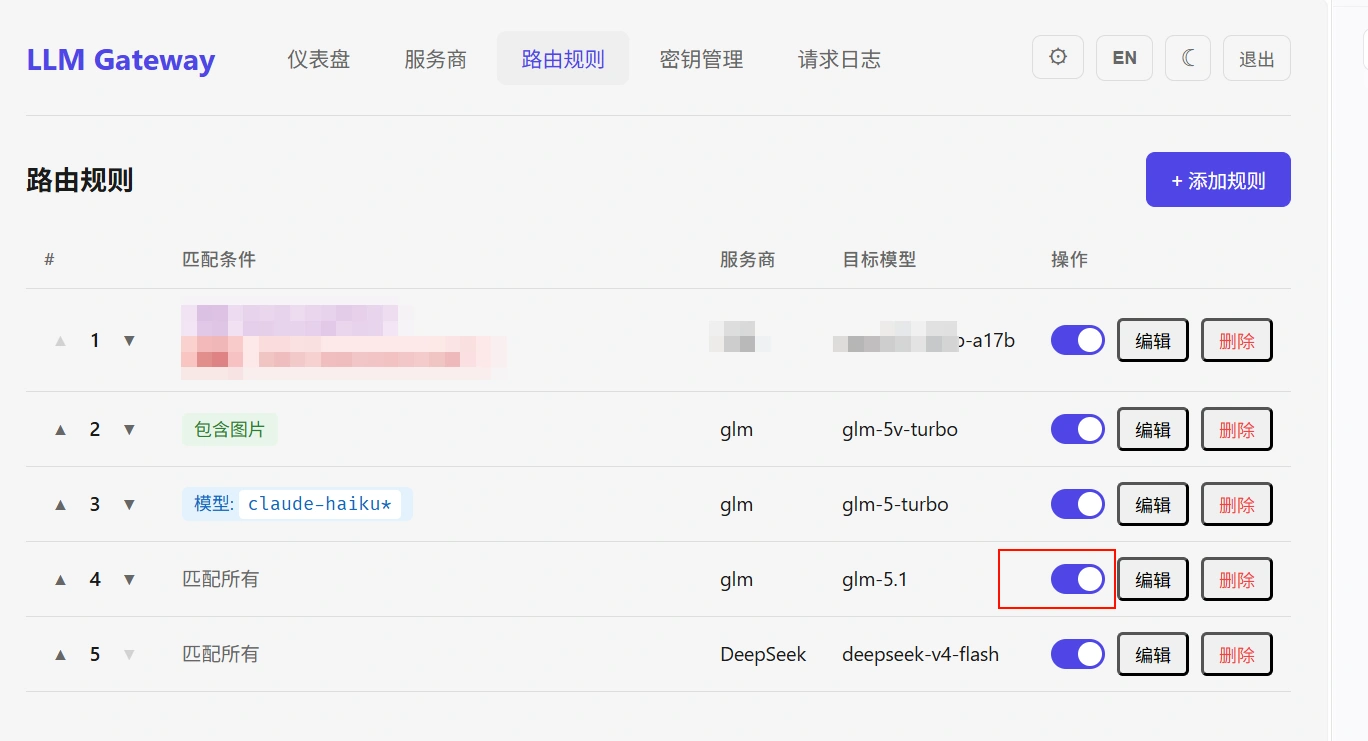
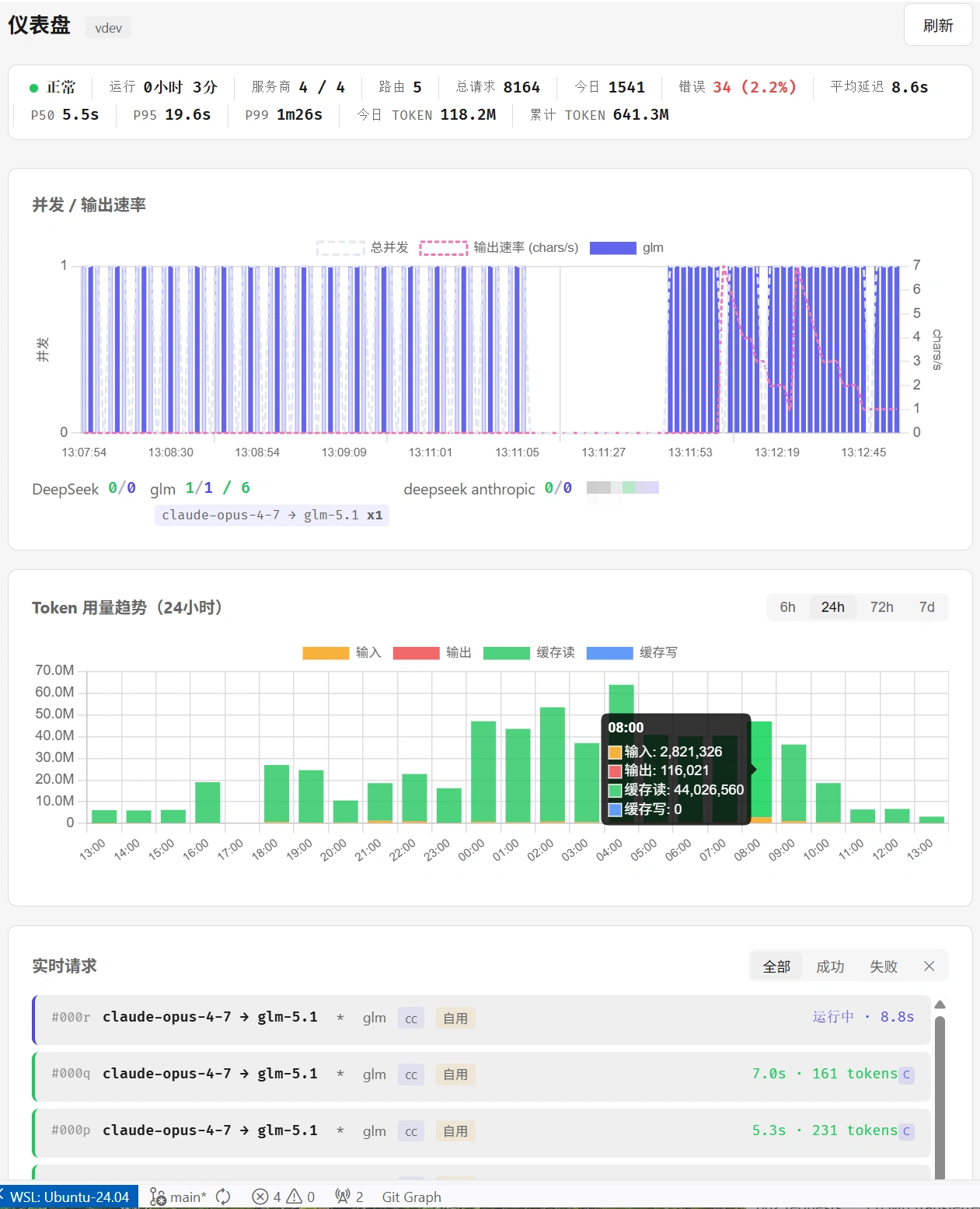
如上图所示,只需要配置一个匹配包含图片的路由规则指向多模态模型就可以做到平时使用更好的glm5.1但是不支持图片输入,一旦粘贴图片,就立刻无感切换多模态模型处理
还有一些神奇的用法,例如cc会将项目路劲拼在提示词中,所以这玩意还可以通过提示词匹配规则来做到公司的项目用公司的token,自己的项目用自己的token
可以在这里一键启用和管理路由规则来切换不同的服务商,例如上图中只需要关闭第四条就会开始使用deepseek 而且不用重启claude code
缺点:模型和服务商的切换会导致缓存命中率略微降低,但我实际使用中感觉也只是会低一点点
项目地址:https://github.com/2234839/llm_gateway ,使用bun构建的,可以在 https://github.com/2234839/llm_gateway/releases 中直接下载单文件使用
仪表盘界面(可以实时看到当前并发和输出速率等信息):